Dive into the practical world of using pattern selection languages to enhance SEO.

The universe is full of patterns, and our websites are no exception.
No matter how unique and different we consider our websites, they will always follow certain patterns, and that’s a good thing, especially as our site grows larger. By recognising these patterns, we can apply our SEO improvements or audits en masse.
However, to take advantage of this, we must know which pattern or element search languages are most useful in each case. Once we identify these, we can leverage those patterns in various ways.
While it’s true that there is a diversity of languages for pattern searching, we will focus on three. Although they may seem complex to learn, the time saved makes the effort worthwhile.
Known as regular expressions, this is used to search for patterns in text strings. It is very powerful and flexible, and if you were to learn just one, this would be the most versatile.
It can be used to: Filter a list of URLs; find information in a database; and locate specific elements or attributes within an HTML document.
It is widely accepted and is currently employed in:
The most common codes are as follows:

Advanced use of these operators will allow us to select exactly the type of URL we desire, accurately, reducing human error and speeding up the task.
Here, we can see a setup to select URLs of fictitious posts containing the word “seo” when they are within the /article/ or /blog/ subdirectory:
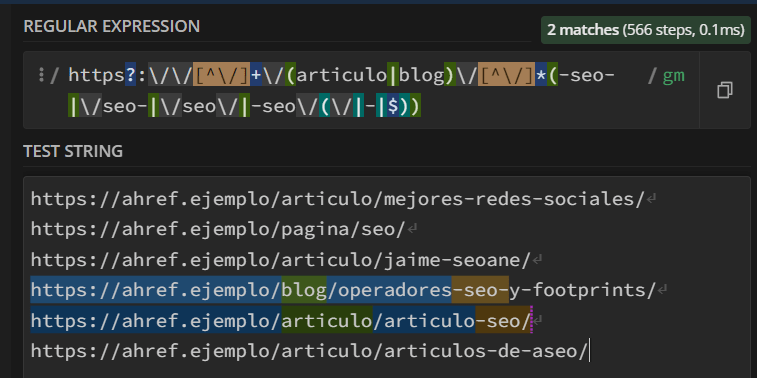
Additionally, what we select in parentheses can be “saved” for substitution in the programming language we are using.
For example, we could perform a mass redirect to change “seo” to “web positioning”, or “article/blog” to “post” when editing a server.
An example of this in a .htaccess:
RedirectMatch 301 ^/(article|blog)/(.?)(-seo-|/seo-|/seo/|-seo/|seo($|/|-))(.)$ /post/$2web-positioning$4$5
Using the dollar signs and their numbering, we can save the regex in the parentheses.
You could apply this to a multitude of options, such as redirecting specific parameters.
Although this is the least known of the three, I’d say it’s the most useful, as it will serve you in various tools when navigating HTML, and also help you understand, modify, and create better with CSS and JavaScript.
Selectors, as the name suggests, are used to select elements, attributes, or values from HTML.
Obviously, to understand selectors, we need to know the basic syntax of any HTML tag.

This will allow us to find any content or element within another tag, with a specific value or property.
For example, if we scrape an entire website’s HTML, it could allow us to see all the links without “http:”
a[href^="http:"]
It also helps us detect all kinds of elements within any HTML page, whether by their tag, attribute, value, and/or parent elements.
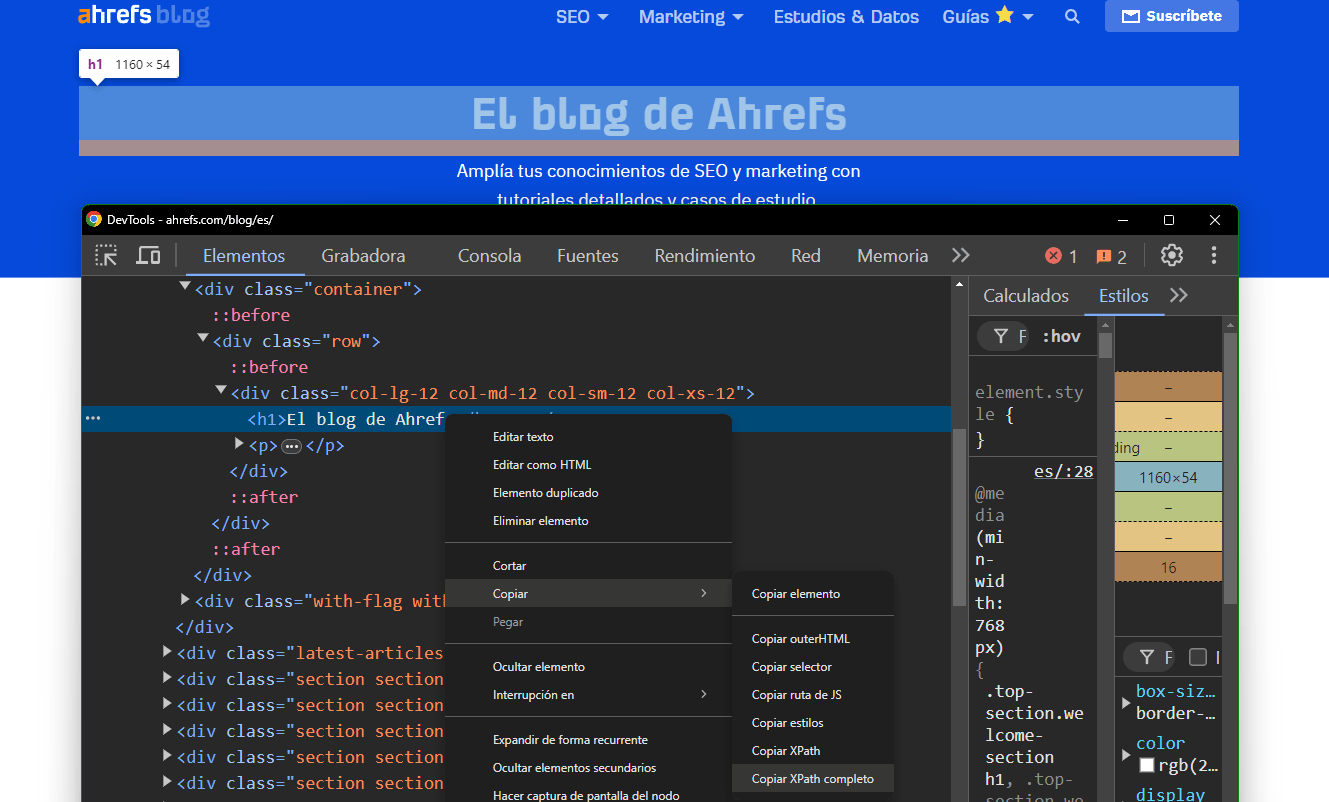
A trick to grab a unique and specific selector from an HTML page is to open the Chrome Console, inspect the element until you find the desired one, and then click on the option to copy the selector. This is represented in the image:
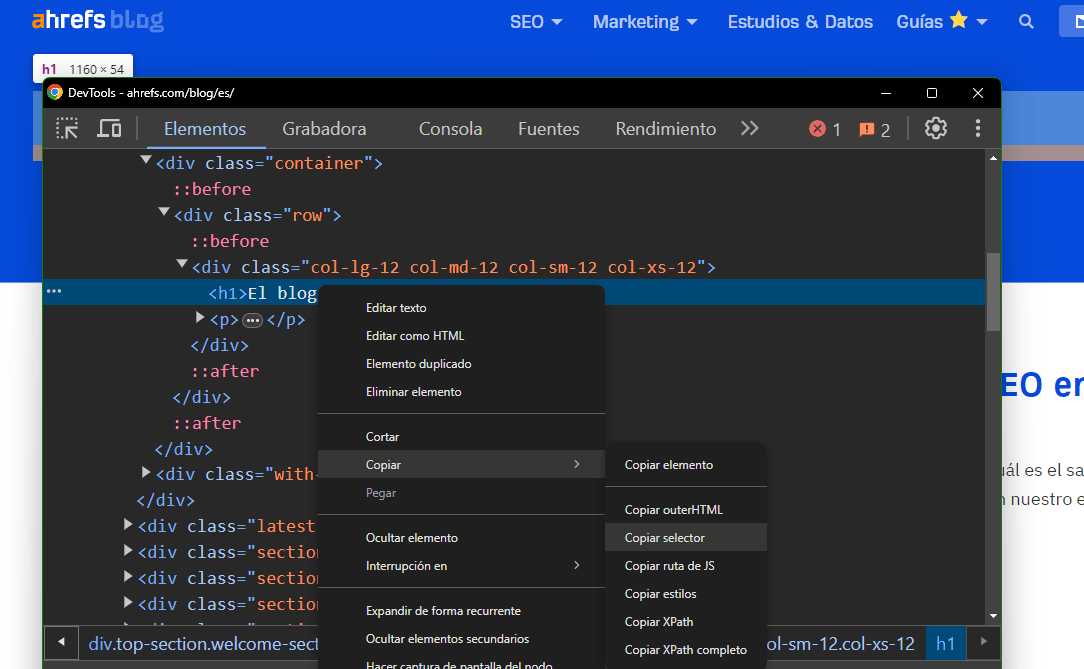
This would be the specific selector for the h1 of the Ahrefs blog:#content > div.top-section.welcome-section > div.container > div > div > h1
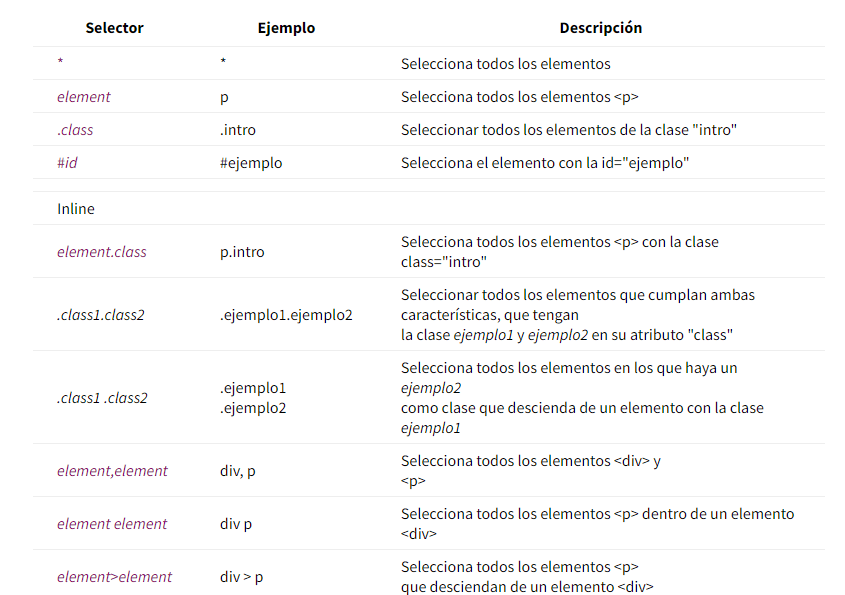
Basic Selectors:
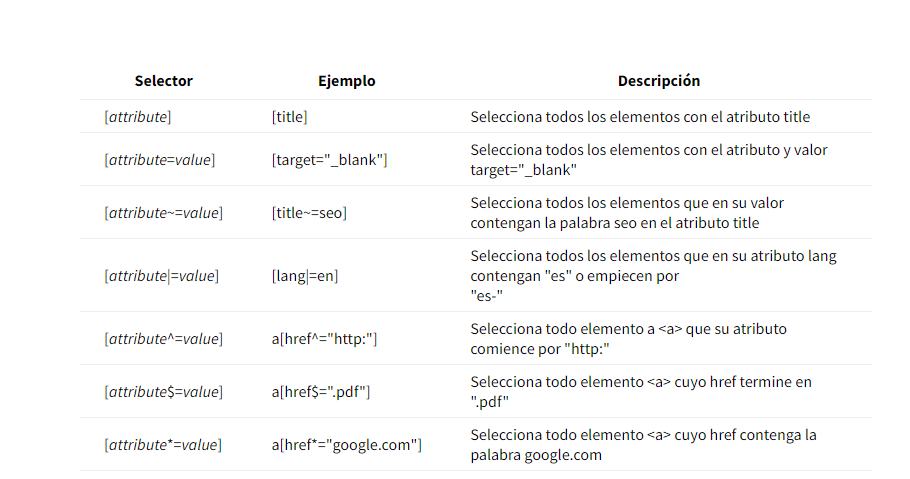
Advanced Selectors:
XPath is used to navigate through elements and attributes in HTML and XML. It works quite similarly to selectors. Originally designed for XML, it is more flexible and slightly more advanced since it allows you to navigate in any direction within the document, unlike selectors (which only allow top-down navigation).
Additionally, XPath is much easier to learn than selectors, but it won’t be useful for CSS or JavaScript. Let’s look at an example of how to extract it using the Chrome Devtools.
This would be the specific XPath for the h1 of the Ahrefs blog:/html/body/div[2]/div/div[1]/div[1]/div/div/h1
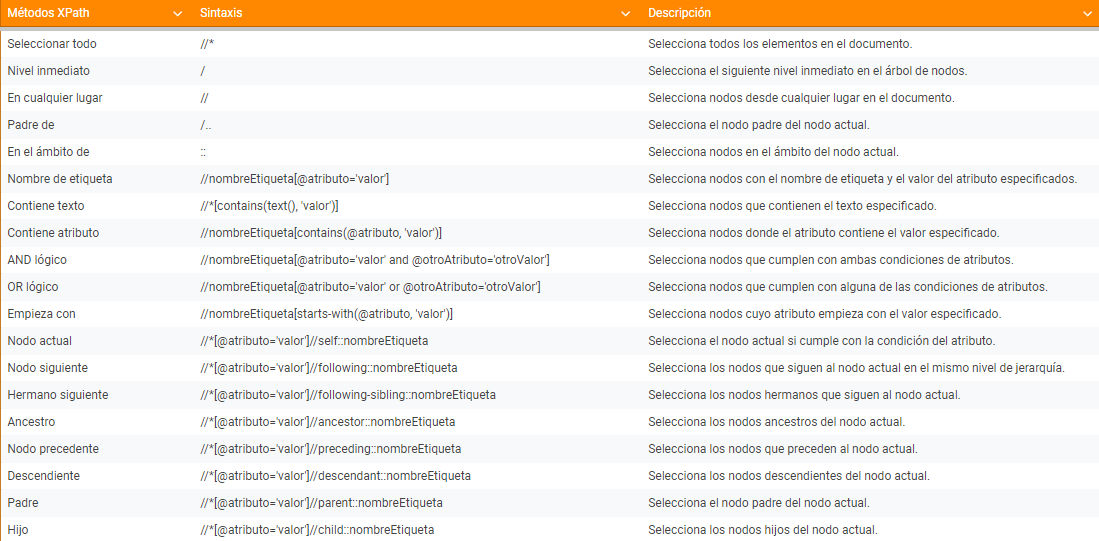
Although it has its complexities, as seen in this “cheatsheet”, it is easier to learn than selectors or regex:
Elements tend to repeat across a website. When implementing any technical change, it’s essential to identify patterns and use them to our advantage. This way, we can make our web environment much more sustainable, scalable, and customisable. This allows us to make the necessary changes with a “single stroke.”
Let’s look at a few examples, as the limit of what can be done is only limited by imagination:
We can prevent the mass indexing of pages even without access to the code, provided we have access to the server. For instance, this code would prevent indexing of all pages under the /tag/ directory in an htaccess file:
<FilesMatch "^tag/.+/"> Header set X-Robots-Tag "noindex"
Or in nginx:
location ~ ^/tag/.+/ { add_header X-Robots-Tag "noindex"; }
It may happen that we are on a website where we cannot alter the server language it’s programmed in. For example, we might have plugins on a site generating unwanted headers, whether in the navbar or the Cookie Policy.
This practice isn’t ideal as it won’t improve site speed, but it is a functional workaround.
Using selectors, we can select that unwanted H1 that’s being generated and remove or modify it (rather than hide it) with JavaScript. This way, we can avoid having poorly structured headings at the time of rendering, provided our site is fast enough.
The same procedure can be applied to repetitive elements on our site that we don’t want appearing in our SERP descriptions. If we don’t have access to the code, but can add scripts, like with Google Tag Manager, we can add a data-nosnippet to specific elements across our site to ensure that content doesn’t appear in our meta descriptions.
It’s quite possible that at some point, we’ll need very specific information from our site, such as the description or a particular section of a product page along with its URL.
In this case, we can use our favourite scraping tool, add an XPath or Selector to find just the repetitive section of our site, and extract a list with only the text we need.
Regex can be widely used in analytics tools such as Google Analytics and its suite, Google Search Console, or Ahrefs. This allows us to conduct a more accurate analysis of the URLs we are interested in. However, it’s also essential to have a hierarchical and organised architecture, which is another reason to follow good SEO practices.
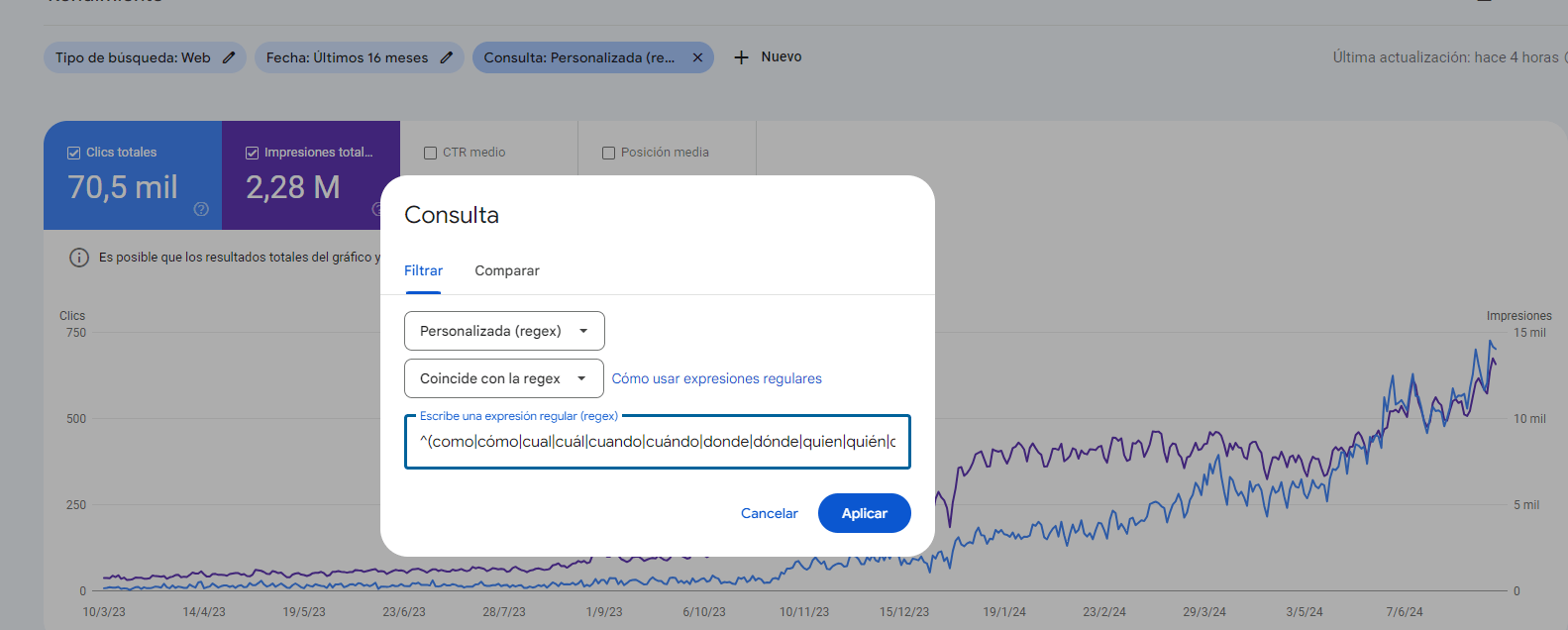
A trick with Regex in Google Search Console can help us find out the types of questions users typically ask on Google to see which pages satisfy certain search intents.
For this, we can enter the expressions that indicate a question in the language we are analysing. Here’s an example in Spanish:
^(como|cómo|cual|cuál|cuando|cuándo|donde|dónde|quien|quién|que|qué|por que|por qué|para que|para qué|cuanto|cuánto|cuantos|cuántos|cuantas|cuántas)b
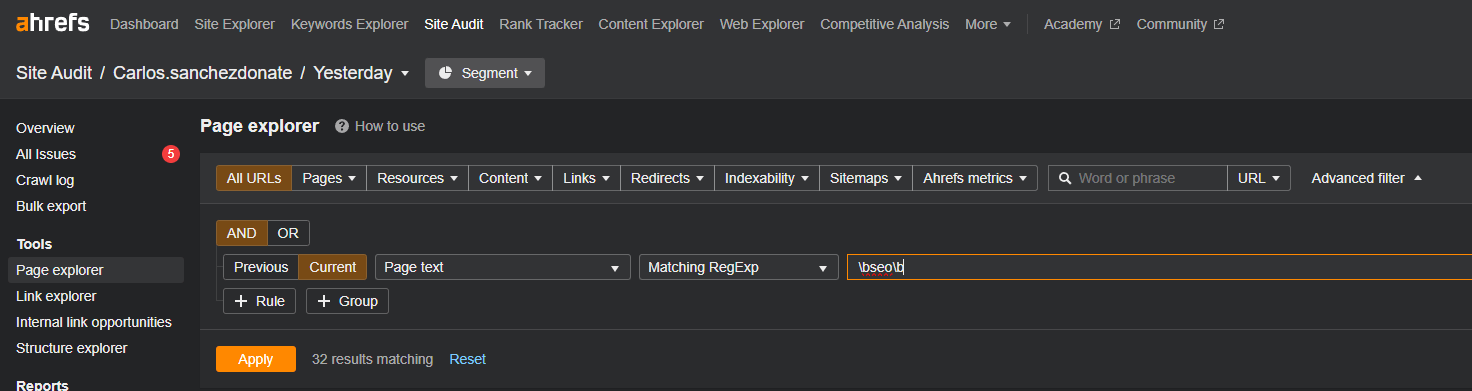
It can be useful for audits and content debugging. If we want to know how often a term appears on our website, we can go to the Site Audit of Ahrefs, access the Page Explorer, and use the advanced filter. You can configure what you want to search for to your liking. In this case, I’ve applied the search in page text, where I can use regex for specific words that are repeated on the site.Site Audit > Page Explorer > Advanced Filter
The tool makes it quite simple as it allows us to filter and add conditions, so we won’t need an especially advanced regex.
Here’s a simple example of how many times the word “SEO” appears separately (to avoid seo-terms):
However, this allows us to quickly search for many terms and variations easily, especially when a word has differences between plural/singular, masculine/feminine (this becomes more useful and fun in other languages like German, which has a neuter gender).
This can be helpful, for example, in detecting words and improving internal linking.
We can also use regex to detect a practice that may have been used on a page in the past.

In this example, we can see how to analyse the number of URLs that pointed to a specific type of page by clicking on the symbol .*, which means a regex search.
I currently offer advanced SEO training in Spanish. Would you like me to create an English version? Let me know!
Tell me you're interested