Ways of deindexing

In SEO, just like in life, there are many ways to reach the same destination — although sometimes with different results.
In today’s article, we will review the different ways to deindex a website, their effects on positioning, the most suitable scenarios to apply them, their limitations, and the myths and controversies that usually surround them.
We will review different ways to implement various deindexing methods and their effects.
| Method | Deindex | Effectiveness | Expiration / Permanence |
| noindex in <meta> | Yes | High | Permanent |
| noindex in HTTP header | Yes | High | Permanent |
| unavailable_after | Partial | Low | Depends on crawling (unreliable) |
| 4XX code (404, 410…) | Yes | Very high | Permanent |
| 5XX code | Eventual | Medium | After one month |
| 3XX code (301, 308) | Indirect | High | Permanent |
| 3XX code (302, 307) | Indirect | Medium | Temporary |
| Meta refresh / JS redirect | Indirect | Low | Temporary |
| Search Console tool | Yes | High (temporary) | Google: 6 months / Bing: 3 months |
| IndexNow | Yes | High | Depends on method sent (404, noindex…) |
| Indexing API (Google) | Yes | Very high | Immediate |
| robots.txt | No | Low | Uncertain |
| Internal nofollow | Indirect | Very low | Depends on the case |
| hreflang without local version | Partial | Very low | Uncertain |
| Orphan pages | Partial | Low | Long-term |
| Misconfigured canonical | Partial | Medium | Uncertain |
| Rendering issues | Partial | Variable | Uncertain |
| Thin Content | Partial | Variable | Uncertain |
| CDN Blocking | Yes | Very high | Immediate |
| Crawl limit | Partial | Medium | Intermittent |
| Robots.txt with 5XX | Yes | High | Gradual, starting after one month |
It is a directive for search engines like Google or Bing, and it can be inserted either through HTML meta tags (always in the Head) or through HTTP headers.
With the well-known “meta robots” tag we can prevent the indexing of the HTML page we choose:
<meta name="robots" content="noindex">
There are elements such as PDFs which, because they are not HTML, can only be correctly assigned a noindex through the HTTP header. This method is known as x-robots.


Regardless of the method used or the order in which it appears, the presence of a noindex directive causes the page not to be indexed or to be deindexed. Even if other tags indicate otherwise, the noindex instruction prevails, as long as the page is crawlable. In meta tags, the most restrictive one will take priority.
In any case, you can also be more specific and prevent indexing by a particular search engine. You would do this by replacing the word “robots” with the user-agent of the search engine in question:
Only to prevent indexing in Google:
<meta name="googlebot" content="noindex">
Only to prevent indexing in Bing:
<meta name="bingbot" content="noindex">
Although in practice, most of the time if someone wants to prevent indexing in one search engine, they do not want indexing in others either. And although it is true that it can be done with programming and that you could serve the HTML robots only to certain user-agents, this is a fairly lightweight HTML standard that allows auditing with a lower margin of human error.
According to Google’s documentation, in the robots meta tag there is another attribute that Google can use, but we must be cautious with it.

The reason to be cautious is that if Google reads the meta tag after the given date, it might consider the page indexable.
<meta name="robots" content="unavailable_after: 2020-09-21">
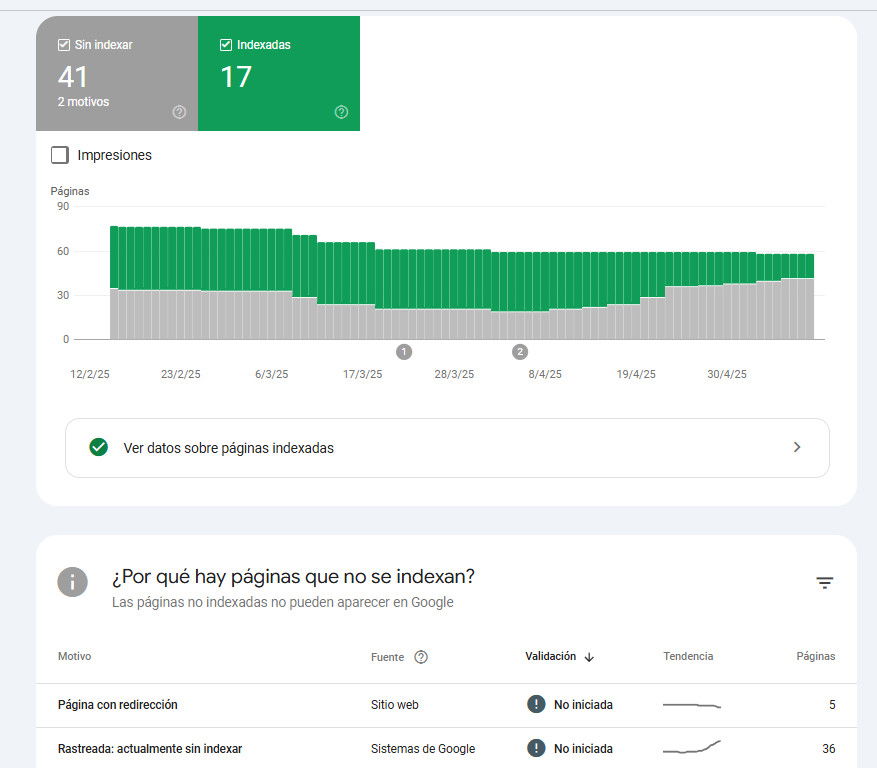
However, tests have also been carried out with days of difference where Google continues considering the page indexable despite having had time to crawl it and later deindex it. The results show that the page remains indexable:

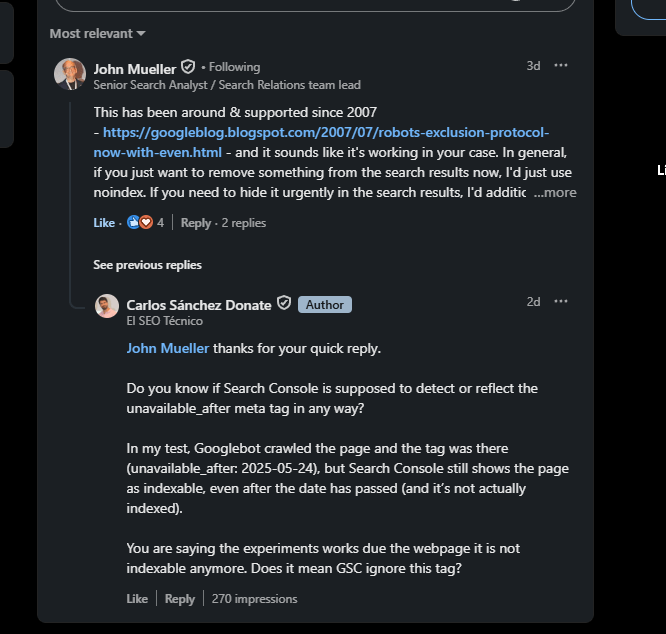
I told John Mueller that I ran a test with the tag <meta name="robots" content="unavailable_after: 2025-05-24">, because according to Google’s official documentation (updated in March 2025), it is still valid. I told him that Googlebot did crawl the page, but in Search Console it appears as indexable, although it is not actually indexed (it is a test page).
I asked him what this means, and proposed three possible explanations:

This was his response:
"This has existed and been supported since 2007 – https://googleblog.blogspot.com/2007/07/robots-exclusion-protocol-now-with-even.html – and it seems to be working in your case.
In general, if you just want to remove something from search results right now, I would simply use
noindex. If you urgently need to hide it from results, I would also use the URL removal tools in Search Console." — John Mueller – Senior Search Analyst at Google 05/27/2025
In summary:
A 4XX code, except 429, indicates that there is no content— either because it does not exist, it no longer exists, access is forbidden or you are not authorized to enter.
Although 4xx and 5xx response codes are called client and server errors respectively, it does not necessarily mean they are SEO "errors" to be corrected; they are useful and necessary information the site provides and that we can use to our advantage — Carlos Sánchez
With this response code you would not only prevent indexing, but in the long run the crawl frequency would decrease.
This response code indicates that the content does not exist either for search engines like Google nor for the user.
The truth is that it is quite an effective way to deindex. It can be done by forcing the response code or removing the page, and if the website is well programmed, the absence of content will automatically produce a 404 or 410.
The 4XX code is a very good deindexing method, but it makes the content inaccessible.
A 5XX code does not directly imply deindexing. In fact, for about a month the results remain almost unchanged.
Google keeps the last version in cache and reduces crawl frequency, assuming it is a temporary error. However, after a month it ends up deindexing the content.
It is actually an ideal response code to avoid indexing when something on the page should not be visible to Google, such as a partially-completed translation pushed to production by mistake.
However, it is a powerful response code and can lead to unexpected results; it should not be used lightly without the supervision of a professional. In this experiment with MJ Cachón we were able to conclude that keeping a continuous 5XX only on robots.txt can lead to the deindexing of the entire site, even if the rest of the site works perfectly.
Redirection is not a direct deindexing method, but it makes the original content inaccessible. So in one way or another, it prevents the original version from being indexable.
If the resulting content is not useful to Google it will eventually be deindexed, and if it still provides value, Google will replace the SERP entry with the new page version.
With response codes 301 and 308 the change will be much faster than with 302 or 307, since the first two are permanent redirects. With 302 and 307 it will be much slower, similar to the 5xx case.
Less orthodox redirects would also work like those from sitebuilders or a meta refresh or JavaScript redirection, though these are less effective.
Major search engines like Bing, Baidu, Yandex or Google have their own search console / webmaster tools that allow the removal of URLs from their index.
These tools are not suitable for permanent deindexing and have an expiration date. Therefore, you must use an additional complementary deindexing method.
Additionally, for safety reasons to avoid accidental mass deindexing, regex cannot be applied. Therefore, all URLs to be removed must either be in a directory or must be submitted one by one.
In fact, they do not allow uploading a list; both in Google and Bing, each request must be submitted individually.
In Google’s case, the deindexing expires after 6 months / 180 days.

In Bing’s case, the deindexing expires after 3 months / 90 days

As the official documentation states, you can send 404s or redirects to notify these changes through the IndexNow standard. You can even send noindex.
As of today, despite vague leaks, Google does not belong to the IndexNow ecosystem.
The IndexNow protocol can also be difficult to implement unless you use IndexNow tools integrated in Ahrefs via Site Audit.

This API should only be used for pages that are a job posting or a live video (visible on that same page).
It is an API for indexing and deindexing instantly since these types of pages have short lifespans.
Although it should only be used for these two content types, it is very effective and allows instant mass deindexing.

There are some practices that may end in deindexing but are very bad practices to apply intentionally.
I’m not including these options as ways to deindex. They are such common mistakes that I feel obligated to list them to emphasize how poor they are:
The robots.txt often leads to confusion because it is a “technical tool” intended to control crawling for certain user-agents.
In reality, it is a standard that Google (other user-agents not necessarily) treats as a directive. However, we can control whether Google crawls a certain directory or not.
However, except in the case of images and videos, robots.txt does not necessarily prevent indexing. Therefore it is not recommended to use robots.txt for deindexing.
As we can see in the example, a site is indexed even though Google cannot crawl it.


A common misunderstanding is that by combining robots.txt with other techniques mentioned above, you avoid both indexing and crawling.
If we block crawling, Google will not be able to see signals from the site such as the response code or a noindex meta tag.
Because of this common error, there have been sites contaminated by a virus that still have all those pages indexed even after removing any trace of the virus simply because Google cannot see that the content no longer exists.
At most, it could be combined with the removal tools, but that is not sustainable. That is, it is not compatible with any other method like noindex or response codes, because it prevents Google from seeing those signals, which is counterproductive.
In conclusion, robots.txt is not a good deindexing method.
As a curiosity, if nofollow is used internally, you could end up sending signals that lead to deindexing of pages.
Although it is not a deindexing technique per se, sometimes language versions are generated without content and the return hreflang is omitted. Google may stop showing that version if it considers that it has no value.
This is not an active technique, but if all internal links to a URL are removed and it receives no traffic (nor external links), meaning the page becomes orphaned, Google may eventually deindex it.
A canonical pointing to another URL is not a directive, but it could lead to deindexing if misconfigured. For example, pointing to the www version when the site is non-www.
This deserves its own article. It can range from sites made with a JS framework using CSR which are not indexable (either due to meta robots or canonical) until JS executes, to sites with 100% VH configured preventing Google from seeing the page content.
If your content, in Google’s eyes, lacks sufficient quality —which may be due to blocked resources, poor rendering, or simply that Google finds it irrelevant— it may lead to deindexing.
Blocking the entire United States or using AI to restrict malicious bots is a common and usually unintentional way to keep URLs out of SERPs.
If either the server or the CDN blocks the U.S. (where Googlebot crawls from) or if very restrictive bot-detection AI is used, it is likely that Googlebot will be prevented from entering the site, causing deindexing.

When a site receives many DDoS attacks or is overloaded by users using automated tools to scrape or crawl, it is normal to limit the crawl rate (requests per minute).
Google tries to crawl very politely, but if a very harsh restriction is set, Google may receive many 429 or 5XX errors. The good news is that this can be easily diagnosed through Search Console or logs.
As I demonstrated with Cachón, a robots.txt can fail to exist or return a 404. If the robots.txt file persistently returns a 5XX error, even if the rest of the site functions correctly, it is likely that within weeks Google will begin mass deindexing of the site.
Deindexing correctly is a way to take care of a website’s health, optimize crawling, and focus efforts on what really deserves to rank.
Ver esta publicación en Instagram
I currently offer advanced SEO training in Spanish. Would you like me to create an English version? Let me know!
Tell me you're interested