Formas de desindexar


En el SEO al igual que en la vida hay muchas formas de llegar al mismo camino. Eso sí en ocasiones con resultados distintos.
En el artículo de hoy revisaremos las distintas formas de desindexación de una web, sus efectos sobre el posicionamiento, los escenarios más adecuados para aplicarlas, sus limitaciones, y los mitos y controversias que suelen rodearlas.
Revisaremos distintas formas de implementar distintos métodos de desindexación y tus efectos.
| Método | Desindexa | Efectividad | Caducidad / Permanencia |
| noindex en <meta> | Sí | Alta | Permanente |
| noindex en encabezado HTTP | Sí | Alta | Permanente |
| unavailable_after | Parcial | Baja | Depende de rastreo (no confiable) |
| Código 4XX (404, 410…) | Sí | Muy alta | Permanente |
| Código 5XX | Eventual | Media | A partir de un mes |
| Código 3XX (301, 308) | Indirecta | Alta | Permanente |
| Código 3XX (302, 307) | Indirecta | Media | Temporal |
| Meta refresh / JS redirect | Indirecta | Baja | Temporal |
| Herramienta Search Console | Sí | Alta (temporal) | Google: 6 meses / Bing: 3 meses |
| IndexNow | Sí | Alta | Según método enviado (404, noindex…) |
| API Indexing (Google) | Sí | Muy alta | Inmediata |
| robots.txt | No | Baja | Incierta |
| nofollow interno | Indirecta | Muy baja | Depende del caso |
| hreflang sin versión local | Parcial | Muy baja | Incierta |
| Páginas huérfanas | Parcial | Baja | A largo plazo |
| canonical mal configurado | Parcial | Media | Incierta |
| Problemas de renderización | Parcial | Variable | Incierta |
| Thin Content | Parcial | Variable | Incierta |
| Bloqueo CDN | Sí | Muy alta | Inmediata |
| Límite de rastreo | Parcial | Media | Intermitente |
| Robots.txt con 5XX | Si | Alta | Gradual a partir de un mes |
Es una directiva para motores de búsqueda como Google o Bing y se pueden insertar tanto por medio de etiquetas meta de HTML (siempre en el Head) como por medio de encabezados HTTP.
Con la archiconocida etiqueta “meta robots” podemos evitar la indexación de la página en HTML que nosotros consideremos:
<meta name="robots" content="noindex">
Hay elementos como PDFs que al no ser HTML la única forma correcta de ponerle un noindex sería por medio del encabezado HTTP, a este método se le conoce como x-robots.


Independientemente del método utilizado o del orden en que aparezca, la presencia de una directiva noindex provoca que la página no sea indexada o sea desindexada. Incluso si existen otras etiquetas que indiquen lo contrario, la instrucción noindex prevalece, siempre que la página sea rastreable. Ya que en metaetiquetas priorizará la más restrictiva.
En cualquiera de los casos, también se puede hacer más específico y evitar la indexación de un motor de búsqueda en particular. Esto lo haríamos sustituyendo la palabra “robots” por el user-agent del motor de búsqueda en cuestión:
Sólo para no indexar en Google:
<meta name="googlebot" content="noindex">
Sólo para no indexar en Bing:
<meta name="bingbot" content="noindex">
Aunque en la práctica, la gran mayor parte de las veces si alguien pretende no indexar en un motor de búsqueda, tampoco lo pretende en otros. Y si bien es cierto que se puede hacer con programación y que salieses el HTML del robots solo con determinados user-agents. Este es un estándar de HTML bastante ligero que permite auditar con menor margen de error humano.
Según la documentación de Google, en la metaetiqueta robots tenemos otro atributo que Google puede utilizar, pero debemos tener cuidado con su empleo.

El motivo por el que hay que tener cuidado, es porque si lee la meta una vez pasada, lo puede considerar como indexable.
<meta name="robots" content="unavailable_after: 2020-09-21">
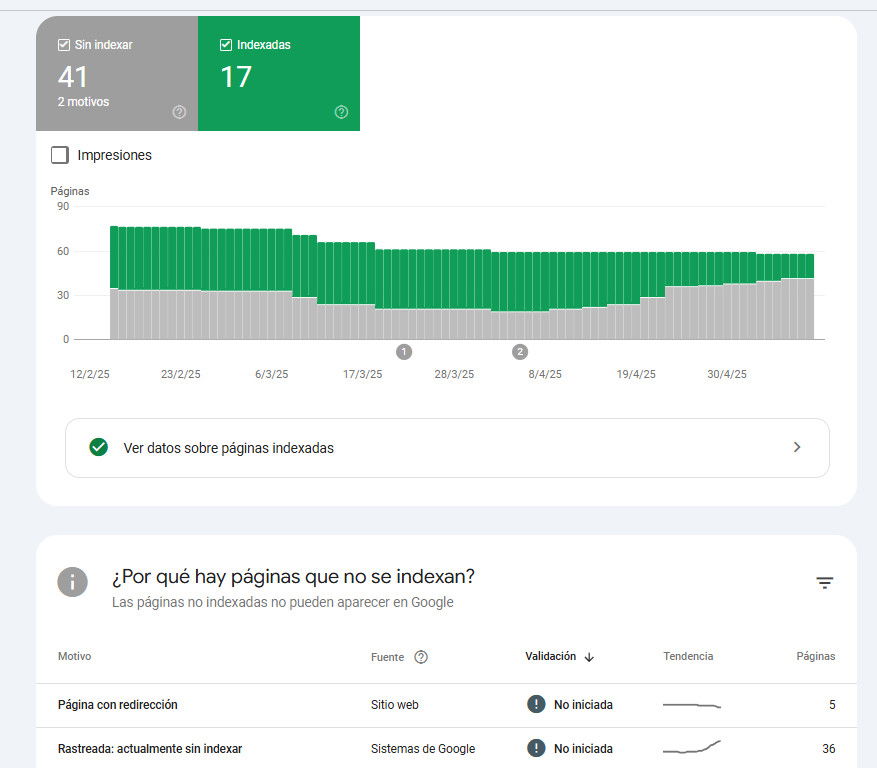
No obstante también se han realizado pruebas con días de diferencia donde Google sigue considerando la página indexable pese a haberle dado tiempo para rastrearla y hacer su posterior desindexación, los resultados es que la página sigue siendo indexable:

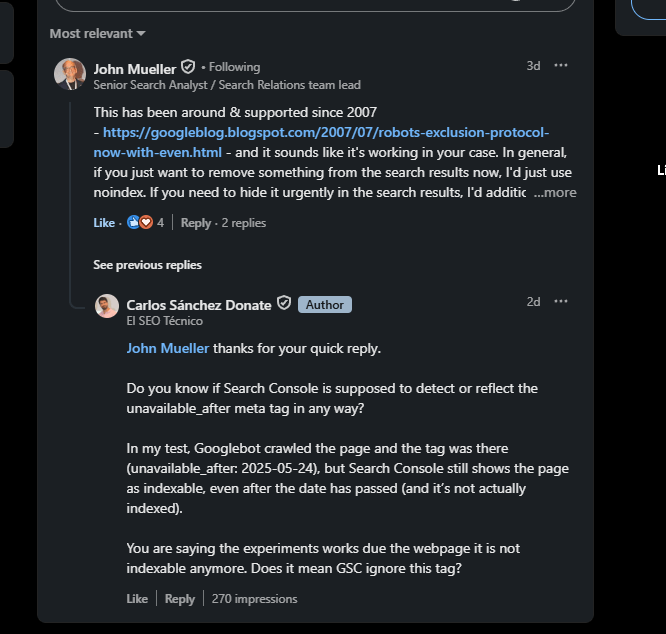
A John Mueller le dije que hice una prueba con la etiqueta <meta name="robots" content="unavailable_after: 2025-05-24">, porque según la documentación oficial de Google (actualizada en marzo de 2025), todavía es válida. Le conté que Googlebot sí rastreó la página, pero que en Search Console aparece como indexable, aunque realmente no está indexada (es una página de prueba).
Le pregunté qué significa eso, y le propuse tres posibles explicaciones:

Esta fue su respuesta:
"Esto existe y es compatible desde 2007 – https://googleblog.blogspot.com/2007/07/robots-exclusion-protocol-now-with-even.html – y parece que está funcionando en tu caso.
En general, si solo quieres eliminar algo de los resultados de búsqueda ahora mismo, yo simplemente usaría
noindex. Si necesitas ocultarlo con urgencia de los resultados, además usaría las herramientas de eliminación de URL en Search Console." — John Mueller – Analista Senior de Búsqueda en Google 27/05/2025
En resumen:
Un código 4XX menos el 429 indica que no hay contenido. Ya sea porque no existe, porque ha dejado de existir, porque está prohibido el acceso o porque no estás autorizado a entrar.
Aunque los códigos de respuesta 4xx y 5xx se llamen error del cliente y de servidor respectivamente, no quiere decir que a la fuerza sean “errores” SEO que haya que corregir, es información útil y necesaria que nos arroja la web y que podemos utilizar a nuestro favor — Carlos Sánchez
Con este código de respuesta no sólo evitaríamos la indexación, sino que a la larga bajaría la frecuencia de rastreo.
Este código de respuesta indicaría que no existe el contenido ni para los motores de búsqueda como Google ni para el usuario.
La realidad es que es una forma bastante eficaz de desindexar. Se puede hacer forzando el código de respuesta o eliminando la página y si la web está bien programada, a falta de contenido arrojará automáticamente un 404 o 410.
El 4XX es un muy buen método de desindexación, pero deja inaccesible el contenido.
Un código 5XX no implica de forma directa una desindexación. En realidad hasta que no pasa aproximadamente un mes se mantienen los resultados casi intactos.
Google mantiene la última versión en caché y baja la frecuencia de rastreo, entendiendo que es un posible error puntual. Sin embargo al cabo de un mes acaba desindexando el contenido.
Realmente es un código de respuesta ideal para evitar la desindexación cuando ocurre algo en la página que Google no debería ver, como una traducción de página que se ha quedado a mitad en la versión de producción.
No obstante, es un código de respuesta potente y puede dar resultados inesperados, no se debe usar a la ligera sin la supervisión de un profesional. En este experimento con MJ cachón pudimos concluir que mantener un código de respuesta 5XX continuado sólo en el robots.txt puede llevar a la desindexación de toda la web, aunque el resto de la web funcione perfectamente.
La redirección no es un método directo de desindexación, pero dejaría inaccesible el contenido original. Por lo que de una u otra forma estaría no dejando indexable la versión original.
Si a Google el contenido resultante no le da resultados lo acabaría desindexando, y si sigue dándoles acabará sustituyendo la posición en las SERPs por la versión de página nueva.
Con el código de respuesta 301 y 308 el cambio sería mucho más rápido que con 302 o 307 ya que las dos primeras son redirecciones permanentes. En el caso del 302 y 307 se haría mucho más lento como ocurre en el 5xx.
También valdrían otro tipo de redirecciones menos ortodoxas como el meta refresh o una redirección por JavaScript, aunque es menos efectivo.
Los motores de búsqueda principales como Bing, Baidu, Yandex o Google cuentan con herramientas propias en sus search console / webmaster que permiten eliminar la indexación de URLs propias en una web.
Estas herramientas no sirven para una desindexación permanente y tienen fecha de caducidad. Por lo que hay que añadirle otro método complementario de desindexación.
Además por seguridad para evitar desindexaciones no deseadas no se puede aplicar regex, por lo que todo el conjunto de URLs que se pretende desindexar está bajo un directorio o hay que subirlas manualmente una a una.
De hecho no permiten subir un listado, tanto en Google como en Bing, cada solicitud hay que subirla una a una.
En el caso de Google la caducidad de la desindexación son 6 meses / 180 días.

En el caso de Bing la caducidad de la desindexación son 3 meses/ 90 días

Como dice la propia documentación, se pueden enviar 404 o redirecciones para notificar estos cambios por medio del estándar indexnow. Incluso puedes mandar noindex.
A día de hoy, pese a vagas filtraciones, Google no pertenece al ecosistema indexnow.
El protocolo indexnow puede ser además difícil de implementar, a menos que utilices herramientas como indexnow integrado en ahrefs a través de site audit.

Esta API solo se debe utilizar bajo páginas que sean una publicación de empleo o un vídeo en directo (que se vea en esa misma página).
Es una API para indexar y desindexar en el momento al ser tipos de páginas con vida fugaz.
Si bien es cierto que solo se debe utilizar para estos dos tipos de contenido, es bastante efectivo y permite una desindexación instantánea en masa.

Hay unas cuantas prácticas que pueden acabar en desindexación pero son una muy mala práctica de cara a aplicarlo.
No pongo estas opciones dignas de mención para que se apliquen como método de desindexación. Pero son errores tan comunes y tan habituales que me veo obligado a recogerlas para enfatizar lo malas prácticas que son:
El robots.txt suele dar lugar a confusión debido a que es una “herramienta técnica” para tener cierto control sobre el rastreo de determinados user-agents.
La realidad es que es un estándar que Google (otros user-agents no) toma como directiva. No obstante podemos controlar si Google rastrea un determinado directorio o no.
Sin embargo, salvo en el caso de imágenes y vídeos, con el robots.txt no evitamos necesariamente la indexación. Por lo que no se recomienda utilizar el robots.txt para desindexar.
Como podemos ver en el ejemplo, hay una web indexada aunque Google no pueda rastrearla.


Existe la mala interpretación común de que si se combina el robots.txt con otra de las técnicas mencionadas, se evita la indexación y el rastreo.
Si bloqueamos el rastreo, Google no será capaz de ver señales de la web como el código de respuesta o una metaetiqueta noindex.
Por culpa de este fallo común se han llegado a ver webs que han sido contaminadas por un virus y tienen todas esas páginas indexadas aún habiendo eliminado cualquier rastro del virus por el simple motivo de que Google no puede ver que ese contenido ya no existe.
En todo caso solo sería combinable con la opción de las herramientas de desindexación, algo que no es sostenible en el tiempo. Es decir, no es combinable con ningún otro método como el noindex o un código de respuesta porque impide a Google ver esas señales, lo que sería contraproducente.
En conclusión, el robots.txt no es un buen método de desindexación.
Como curiosidad, si se usa nofollow de forma interna, podrías acabar dando señales que acaben en desindexaciones de páginas
Aunque no es una técnica de desindexación como tal, a veces se generan versiones de idioma sin contenido y se omite la hreflang de vuelta. Google puede dejar de mostrar esa versión por considerar que no tiene valor.
Esto no es una técnica activa, pero si se eliminan todos los enlaces internos a una URL y no recibe tráfico (ni enlaces externos)es decir, que la página queda huérfana, Google puede acabar considerándola desindexándola con el tiempo.
El canonical apuntando a otra URL no es una directiva, pero podría acabar en desindexación en caso de estar mal configurado. Por ejemplo apuntar a la versión de la web con www cuando la web es sin www.
Esto se merecería una publicación en sí mismo. Pero puede ir desde webs que están hechas en un framework de JS con CSR (Client Side Rendering) las cuales no son indexables (ya sea por meta robots o por canonical) hasta que se aplica JS, hasta webs que tienen configurado un VH del 100% y no permiten a Google ver el contenido de la página.
Si tu contenido a ojos de Google no tiene la calidad suficiente. Lo cual puede ser porque tiene elementos bloqueados, mala renderización o que realmente el contenido le parece irrelevante. Puede ser otra metodología de desindexación.
Bloquear a todo Estados Unidos o dejar a la IA para bloquear bots maliciosos de forma restrictiva es una buena forma y normalmente inintencionada de mantener las URLs de una web fuera de las SERPs.
Tanto si desde el servidor como con el CDN bloqueas EEUU (desde donde rastrea Googlebot) o configuras una opción muy restrictiva de inteligencia artificial para detectar bots, es muy posible que impidas a Googlebot entrar a tu web, provocando de esa forma una desindexación.

Cuando una web recibe muchos ataques DDOS o le saturan la web debido a la cantidad de usuarios que utilizan herramientas automáticas para scrapear o rastrear la web, es normal tomar la medida de limitar el rastreo en la web (cantidad de solicitudes por minuto).
Google intenta rastrear de una forma muy poco agresiva, pero es posible que si se ha puesto una restricción muy dura, Google acabe recibiendo muchos 429 o 5XX. Lo bueno es que esto se puede diagnosticar fácil por medio de la Search Console o por Logs.
Como demostré junto a cachón, un robots.txt puede no existir o dar un 404. PSi el archivo robots.txt devuelve un error 5XX de forma persistente, aunque el resto del sitio funcione correctamente, es probable que en cuestión de semanas Google comience a desindexar masivamente las páginas del sitio.
Desindexar de una forma correcta es una manera de cuidar la salud de una web, optimizar el rastreo y centrar los esfuerzos en lo que realmente merece posicionar.
Ver esta publicación en Instagram
Te falta mi máster. Accede a una formación avanzada que te permitirá aplicar e implementar SEO en cualquier tipo de WEB
¡Accede al Máster de SEO Técnico!